How to properly cite our product/service in your workWe strongly recommend using this: RNA Data Analysis (Hologic Diagenode Cat# G02030005). Click here to copy to clipboard. Using our products or services in your publication? Let us know! |
MGcount: a total RNA-seq quantification tool to address multi-mappingand multi-overlapping alignments ambiguity in non-coding transcripts |
RNA Data Analysis
- Protocols
- Documents
- Related
-
Get a quote×
Get a quote
You are about to request a quote for RNA Data Analysis. Fill out the form below and we will be in touch with you very soon.
All * fields are mandatory
Catalog Number
Format
G02030005
Total RNA sequencing (RNA-Seq) detects both coding and noncoding RNAs and is typically used to measure gene and transcript abundance as well as to identify novel components of the transcriptome. Messenger RNA-Seq focuses on the quantification of gene expression, the identification of unknown transcripts, the discovery of alternative splicing and gene fusion events. And finally, small non-coding RNA sequencing (sncRNA-Seq) will detect small (<100 nucleotides long) RNAs that operate as key regulators in cellular processes.
What do we provide with the analysis?
This analysis provides information for either genes or isoforms with their expression levels.
Standard Analysis
- Summary statistics (total sequenced reads, total mapping reads, uniquely aligned reads, PCR duplicates, number of genes detected, average read density per gene, number of highly expressed genes, etc.)
- Trimmed and filtered reads in fastQ files after sequencing QC
- BAM sorted files from alignment to reference genome or transcriptome (indexed bam files and bigwig files included)
- Matrix with expression abundance obtained with specialized quantification tool MGCount (software developed by Diagenode). A table of MG communities linking each original feature in the GTF file with the resultant count matrix and metadata feature identifiers.
Advanced Analysis
- Comparative analysis (also called differential analysis) aimed at finding differentially expressed genes (DEGs) between two groups of samples
- Functional gene annotation
- Gene ontology enrichment analysis on DEGs
- Pathway enrichment analysis on DEGs (KEGG or DOSE for human samples)
- Alternative splicing analysis
- Gene fusion analysis
- Novel transcript identification
Customized Analysis
If you require a type of analysis that is not in the previous list, please consult with our expert bioinformatics team.
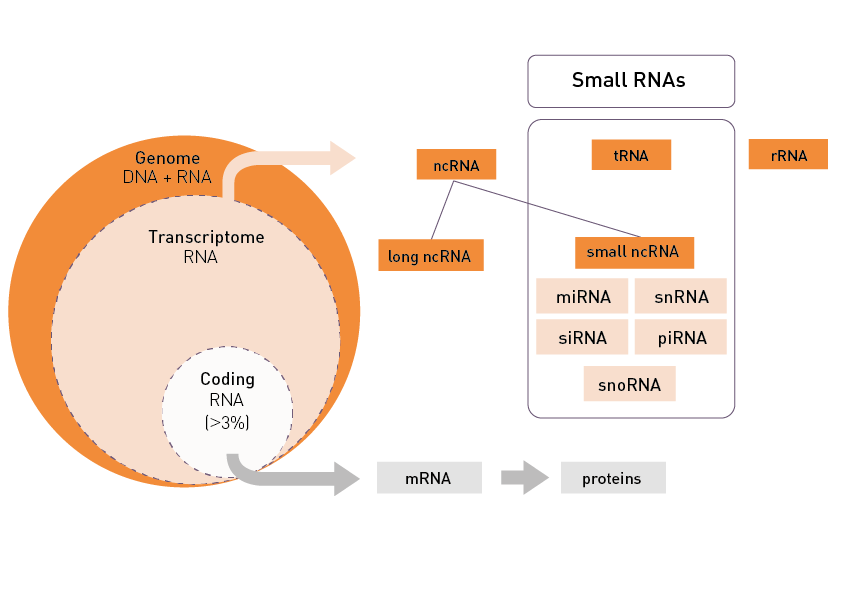
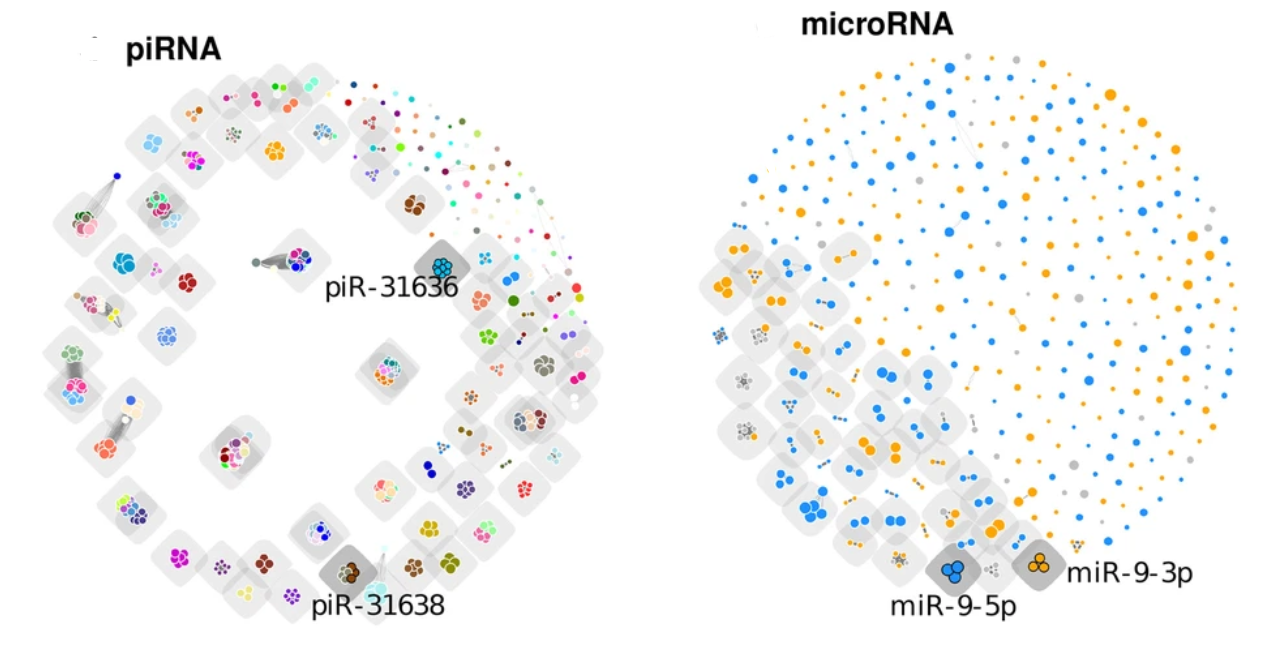
MGcount: Diagenode has developed a bioinformatics software for counting whole-transcriptome RNA-seq reads from one or more input alignment files. It is specially designed to incorporate multi-mapping and multi-overlapping reads in the quantification using a flexible methodology that is compatible with any biotype. At the end of its execution, it produces a count matrix, compatible with any downstream analysis.
- Publications
(Notice): Undefined variable: solution_of_interest [APP/View/Products/view.ctp, line 747]Code Context$errorType = self::getErrorType($code);self::logToDatabase( $errorType, $description, $file, $line);return parent::handleError( $errorType, $description, $file, $line, $context);$viewFile = '/var/www/dev.diagenode.com/app/View/Products/view.ctp' $dataForView = array( 'language' => 'en', 'meta_keywords' => '', 'meta_description' => 'RNA-seq data analysis service is made to extract information from a large variety of RNA-seq data (small RNA, mRNA and much more).', 'meta_title' => 'RNA Data Analysis Services | Diagenode', 'product' => array( 'Product' => array( 'id' => '3062', 'antibody_id' => null, 'name' => 'RNA Data Analysis', 'description' => '<p>Total RNA sequencing (RNA-Seq) detects both coding and noncoding RNAs and is typically used to measure gene and transcript abundance as well as to identify novel components of the transcriptome. Messenger RNA-Seq focuses on the quantification of gene expression, the identification of unknown transcripts, the discovery of alternative splicing and gene fusion events. And finally, small non-coding RNA sequencing (sncRNA-Seq) will detect small (<100 nucleotides long) RNAs that operate as key regulators in cellular processes.</p> <div class="extra-spaced"> <h2>What do we provide with the analysis?</h2> <p>This analysis provides information for either genes or isoforms with their expression levels.</p> <h3 class="diacol" style="font-weight: 100;">Standard Analysis</h3> <ul style="list-style-type: circle;"> <li>Summary statistics (total sequenced reads, total mapping reads, uniquely aligned reads, PCR duplicates, number of genes detected, average read density per gene, number of highly expressed genes, etc.)</li> <li>Trimmed and filtered reads in fastQ files after sequencing QC</li> <li>BAM sorted files from alignment to reference genome or transcriptome (indexed bam files and bigwig files included)</li> <li>Matrix with expression abundance obtained with specialized quantification tool MGCount (<a href="https://doi.org/10.1186/s12859-021-04544-3">software developed by Diagenode</a>). A table of MG communities linking each original feature in the GTF file with the resultant count matrix and metadata feature identifiers.</li> </ul> <h3 class="diacol" style="font-weight: 100;">Advanced Analysis</h3> <ul style="list-style-type: circle;"> <li>Comparative analysis (also called differential analysis) aimed at finding differentially expressed genes (DEGs) between two groups of samples</li> <li>Functional gene annotation</li> <li>Gene ontology enrichment analysis on DEGs</li> <li>Pathway enrichment analysis on DEGs (KEGG or DOSE for human samples)</li> <li>Alternative splicing analysis</li> <li>Gene fusion analysis</li> <li>Novel transcript identification</li> </ul> <h3 class="diacol" style="font-weight: 100;">Customized Analysis</h3> <p class="text-left">If you require a type of analysis that is not in the previous list, <a href="#" data-reveal-id="quoteModal-3062">please consult with our expert bioinformatics team</a>.</p> </div> <div><center><img src="https://www.diagenode.com/img/product/services/RNA-theorie.png" /></center></div> <p><a href="https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-021-04544-3">MGcount</a>: Diagenode has developed a bioinformatics software for counting whole-transcriptome RNA-seq reads from one or more input alignment files. It is specially designed to incorporate multi-mapping and multi-overlapping reads in the quantification using a flexible methodology that is compatible with any biotype. At the end of its execution, it produces a count matrix, compatible with any downstream analysis.</p> <center><img src="https://www.diagenode.com/img/product/services/mGcount-img.png" width="600px" /></center>', 'label1' => '', 'info1' => '', 'label2' => '', 'info2' => '', 'label3' => '', 'info3' => '', 'format' => '', 'catalog_number' => 'G02030005', 'old_catalog_number' => '', 'sf_code' => '', 'type' => 'ACC', 'search_order' => '', 'price_EUR' => '', 'price_USD' => '', 'price_GBP' => '', 'price_JPY' => '', 'price_CNY' => '', 'price_AUD' => '', 'country' => 'ALL', 'except_countries' => 'None', 'quote' => true, 'in_stock' => false, 'featured' => true, 'no_promo' => false, 'online' => true, 'master' => true, 'last_datasheet_update' => '', 'slug' => 'rna-data-analysis', 'meta_title' => 'RNA Data Analysis Services | Diagenode', 'meta_keywords' => '', 'meta_description' => 'RNA-seq data analysis service is made to extract information from a large variety of RNA-seq data (small RNA, mRNA and much more).', 'modified' => '2022-11-22 15:26:24', 'created' => '2020-03-26 10:04:58', 'locale' => 'eng' ), 'Antibody' => array( 'host' => '*****', 'id' => null, 'name' => null, 'description' => null, 'clonality' => null, 'isotype' => null, 'lot' => null, 'concentration' => null, 'reactivity' => null, 'type' => null, 'purity' => null, 'classification' => null, 'application_table' => null, 'storage_conditions' => null, 'storage_buffer' => null, 'precautions' => null, 'uniprot_acc' => null, 'slug' => null, 'meta_keywords' => null, 'meta_description' => null, 'modified' => null, 'created' => null, 'select_label' => null ), 'Slave' => array(), 'Group' => array(), 'Related' => array(), 'Application' => array(), 'Category' => array(), 'Document' => array(), 'Feature' => array(), 'Image' => array(), 'Promotion' => array(), 'Protocol' => array(), 'Publication' => array( (int) 0 => array( [maximum depth reached] ) ), 'Testimonial' => array(), 'Area' => array(), 'SafetySheet' => array() ), 'fromEmail' => 'dev.diagenode.com' ) $language = 'en' $meta_keywords = '' $meta_description = 'RNA-seq data analysis service is made to extract information from a large variety of RNA-seq data (small RNA, mRNA and much more).' $meta_title = 'RNA Data Analysis Services | Diagenode' $product = array( 'Product' => array( 'id' => '3062', 'antibody_id' => null, 'name' => 'RNA Data Analysis', 'description' => '<p>Total RNA sequencing (RNA-Seq) detects both coding and noncoding RNAs and is typically used to measure gene and transcript abundance as well as to identify novel components of the transcriptome. Messenger RNA-Seq focuses on the quantification of gene expression, the identification of unknown transcripts, the discovery of alternative splicing and gene fusion events. And finally, small non-coding RNA sequencing (sncRNA-Seq) will detect small (<100 nucleotides long) RNAs that operate as key regulators in cellular processes.</p> <div class="extra-spaced"> <h2>What do we provide with the analysis?</h2> <p>This analysis provides information for either genes or isoforms with their expression levels.</p> <h3 class="diacol" style="font-weight: 100;">Standard Analysis</h3> <ul style="list-style-type: circle;"> <li>Summary statistics (total sequenced reads, total mapping reads, uniquely aligned reads, PCR duplicates, number of genes detected, average read density per gene, number of highly expressed genes, etc.)</li> <li>Trimmed and filtered reads in fastQ files after sequencing QC</li> <li>BAM sorted files from alignment to reference genome or transcriptome (indexed bam files and bigwig files included)</li> <li>Matrix with expression abundance obtained with specialized quantification tool MGCount (<a href="https://doi.org/10.1186/s12859-021-04544-3">software developed by Diagenode</a>). A table of MG communities linking each original feature in the GTF file with the resultant count matrix and metadata feature identifiers.</li> </ul> <h3 class="diacol" style="font-weight: 100;">Advanced Analysis</h3> <ul style="list-style-type: circle;"> <li>Comparative analysis (also called differential analysis) aimed at finding differentially expressed genes (DEGs) between two groups of samples</li> <li>Functional gene annotation</li> <li>Gene ontology enrichment analysis on DEGs</li> <li>Pathway enrichment analysis on DEGs (KEGG or DOSE for human samples)</li> <li>Alternative splicing analysis</li> <li>Gene fusion analysis</li> <li>Novel transcript identification</li> </ul> <h3 class="diacol" style="font-weight: 100;">Customized Analysis</h3> <p class="text-left">If you require a type of analysis that is not in the previous list, <a href="#" data-reveal-id="quoteModal-3062">please consult with our expert bioinformatics team</a>.</p> </div> <div><center><img src="https://www.diagenode.com/img/product/services/RNA-theorie.png" /></center></div> <p><a href="https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-021-04544-3">MGcount</a>: Diagenode has developed a bioinformatics software for counting whole-transcriptome RNA-seq reads from one or more input alignment files. It is specially designed to incorporate multi-mapping and multi-overlapping reads in the quantification using a flexible methodology that is compatible with any biotype. At the end of its execution, it produces a count matrix, compatible with any downstream analysis.</p> <center><img src="https://www.diagenode.com/img/product/services/mGcount-img.png" width="600px" /></center>', 'label1' => '', 'info1' => '', 'label2' => '', 'info2' => '', 'label3' => '', 'info3' => '', 'format' => '', 'catalog_number' => 'G02030005', 'old_catalog_number' => '', 'sf_code' => '', 'type' => 'ACC', 'search_order' => '', 'price_EUR' => '', 'price_USD' => '', 'price_GBP' => '', 'price_JPY' => '', 'price_CNY' => '', 'price_AUD' => '', 'country' => 'ALL', 'except_countries' => 'None', 'quote' => true, 'in_stock' => false, 'featured' => true, 'no_promo' => false, 'online' => true, 'master' => true, 'last_datasheet_update' => '', 'slug' => 'rna-data-analysis', 'meta_title' => 'RNA Data Analysis Services | Diagenode', 'meta_keywords' => '', 'meta_description' => 'RNA-seq data analysis service is made to extract information from a large variety of RNA-seq data (small RNA, mRNA and much more).', 'modified' => '2022-11-22 15:26:24', 'created' => '2020-03-26 10:04:58', 'locale' => 'eng' ), 'Antibody' => array( 'host' => '*****', 'id' => null, 'name' => null, 'description' => null, 'clonality' => null, 'isotype' => null, 'lot' => null, 'concentration' => null, 'reactivity' => null, 'type' => null, 'purity' => null, 'classification' => null, 'application_table' => null, 'storage_conditions' => null, 'storage_buffer' => null, 'precautions' => null, 'uniprot_acc' => null, 'slug' => null, 'meta_keywords' => null, 'meta_description' => null, 'modified' => null, 'created' => null, 'select_label' => null ), 'Slave' => array(), 'Group' => array(), 'Related' => array(), 'Application' => array(), 'Category' => array(), 'Document' => array(), 'Feature' => array(), 'Image' => array(), 'Promotion' => array(), 'Protocol' => array(), 'Publication' => array( (int) 0 => array( 'id' => '4252', 'name' => 'MGcount: a total RNA-seq quantification tool to address multi-mappingand multi-overlapping alignments ambiguity in non-coding transcripts', 'authors' => 'Hita Andrea, Brocart Gilles, Fernandez Ana, Rehmsmeier Marc, Alemany Anna, Schvartzman Sol', 'description' => '<p>Background Total-RNA sequencing (total-RNA-seq) allows the simultaneous study of both the coding and the non-coding transcriptome. Yet, computational pipelines have traditionally focused on particular biotypes, making assumptions that are not fullfilled by total-RNA-seq datasets. Transcripts from distinct RNA biotypes vary in length, biogenesis, and function, can overlap in a genomic region, and may be present in the genome with a high copy number. Consequently, reads from total-RNA-seq libraries may cause ambiguous genomic alignments, demanding for flexible quantification approaches. Results Here we present Multi-Graph count (MGcount), a total-RNA-seq quantification tool combining two strategies for handling ambiguous alignments. First, MGcount assigns reads hierarchically to small-RNA and long-RNA features to account for length disparity when transcripts overlap in the same genomic position. Next, MGcount aggregates RNA products with similar sequences where reads systematically multi-map using a graph-based approach. MGcount outputs a transcriptomic count matrix compatible with RNA-sequencing downstream analysis pipelines, with both bulk and single-cell resolution, and the graphs that model repeated transcript structures for different biotypes. The software can be used as a python module or as a single-file executable program. Conclusions MGcount is a flexible total-RNA-seq quantification tool that successfully integrates reads that align to multiple genomic locations or that overlap with multiple gene features. Its approach is suitable for the simultaneous estimation of protein-coding, long non-coding and small non-coding transcript concentration, in both precursor and processed forms. Both source code and compiled software are available at https://github.com/hitaandrea/MGcount. Supplementary Information The online version contains supplementary material available at 10.1186/s12859-021-04544-3.</p>', 'date' => '2022-01-01', 'pmid' => 'https://www.ncbi.nlm.nih.gov/pubmed/35030988', 'doi' => '10.1186/s12859-021-04544-3', 'modified' => '2022-05-20 09:42:23', 'created' => '2022-05-19 10:41:50', 'ProductsPublication' => array( [maximum depth reached] ) ) ), 'Testimonial' => array(), 'Area' => array(), 'SafetySheet' => array() ) $fromEmail = 'dev.diagenode.com' $country = 'US' $countries_allowed = array( (int) 0 => 'CA', (int) 1 => 'US', (int) 2 => 'IE', (int) 3 => 'GB', (int) 4 => 'DK', (int) 5 => 'NO', (int) 6 => 'SE', (int) 7 => 'FI', (int) 8 => 'NL', (int) 9 => 'BE', (int) 10 => 'LU', (int) 11 => 'FR', (int) 12 => 'DE', (int) 13 => 'CH', (int) 14 => 'AT', (int) 15 => 'ES', (int) 16 => 'IT', (int) 17 => 'PT' ) $outsource = false $other_formats = array() $edit = '' $testimonials = '' $featured_testimonials = '' $related_products = '' $rrbs_service = array( (int) 0 => (int) 1894, (int) 1 => (int) 1895 ) $chipseq_service = array( (int) 0 => (int) 2683, (int) 1 => (int) 1835, (int) 2 => (int) 1836, (int) 3 => (int) 2684, (int) 4 => (int) 1838, (int) 5 => (int) 1839, (int) 6 => (int) 1856 ) $labelize = object(Closure) { } $old_catalog_number = '' $label = '<img src="/img/banners/banner-customizer-back.png" alt=""/>' $publication = array( 'id' => '4252', 'name' => 'MGcount: a total RNA-seq quantification tool to address multi-mappingand multi-overlapping alignments ambiguity in non-coding transcripts', 'authors' => 'Hita Andrea, Brocart Gilles, Fernandez Ana, Rehmsmeier Marc, Alemany Anna, Schvartzman Sol', 'description' => '<p>Background Total-RNA sequencing (total-RNA-seq) allows the simultaneous study of both the coding and the non-coding transcriptome. Yet, computational pipelines have traditionally focused on particular biotypes, making assumptions that are not fullfilled by total-RNA-seq datasets. Transcripts from distinct RNA biotypes vary in length, biogenesis, and function, can overlap in a genomic region, and may be present in the genome with a high copy number. Consequently, reads from total-RNA-seq libraries may cause ambiguous genomic alignments, demanding for flexible quantification approaches. Results Here we present Multi-Graph count (MGcount), a total-RNA-seq quantification tool combining two strategies for handling ambiguous alignments. First, MGcount assigns reads hierarchically to small-RNA and long-RNA features to account for length disparity when transcripts overlap in the same genomic position. Next, MGcount aggregates RNA products with similar sequences where reads systematically multi-map using a graph-based approach. MGcount outputs a transcriptomic count matrix compatible with RNA-sequencing downstream analysis pipelines, with both bulk and single-cell resolution, and the graphs that model repeated transcript structures for different biotypes. The software can be used as a python module or as a single-file executable program. Conclusions MGcount is a flexible total-RNA-seq quantification tool that successfully integrates reads that align to multiple genomic locations or that overlap with multiple gene features. Its approach is suitable for the simultaneous estimation of protein-coding, long non-coding and small non-coding transcript concentration, in both precursor and processed forms. Both source code and compiled software are available at https://github.com/hitaandrea/MGcount. Supplementary Information The online version contains supplementary material available at 10.1186/s12859-021-04544-3.</p>', 'date' => '2022-01-01', 'pmid' => 'https://www.ncbi.nlm.nih.gov/pubmed/35030988', 'doi' => '10.1186/s12859-021-04544-3', 'modified' => '2022-05-20 09:42:23', 'created' => '2022-05-19 10:41:50', 'ProductsPublication' => array( 'id' => '5682', 'product_id' => '3062', 'publication_id' => '4252' ) ) $externalLink = ' <a href="https://www.ncbi.nlm.nih.gov/pubmed/35030988" target="_blank"><i class="fa fa-external-link"></i></a>'CustomErrorHandler::handleError() - APP/Lib/CustomErrorHandler.php, line 9 include - APP/View/Products/view.ctp, line 747 View::_evaluate() - CORE/Cake/View/View.php, line 971 View::_render() - CORE/Cake/View/View.php, line 933 View::render() - CORE/Cake/View/View.php, line 473 Controller::render() - CORE/Cake/Controller/Controller.php, line 963 ProductsController::slug() - APP/Controller/ProductsController.php, line 1055 ReflectionMethod::invokeArgs() - [internal], line ?? Controller::invokeAction() - CORE/Cake/Controller/Controller.php, line 491 Dispatcher::_invoke() - CORE/Cake/Routing/Dispatcher.php, line 193 Dispatcher::dispatch() - CORE/Cake/Routing/Dispatcher.php, line 167 [main] - APP/webroot/index.php, line 118
(Notice): Undefined variable: header [APP/View/Products/view.ctp, line 747]Code Context$errorType = self::getErrorType($code);self::logToDatabase( $errorType, $description, $file, $line);return parent::handleError( $errorType, $description, $file, $line, $context);$viewFile = '/var/www/dev.diagenode.com/app/View/Products/view.ctp' $dataForView = array( 'language' => 'en', 'meta_keywords' => '', 'meta_description' => 'RNA-seq data analysis service is made to extract information from a large variety of RNA-seq data (small RNA, mRNA and much more).', 'meta_title' => 'RNA Data Analysis Services | Diagenode', 'product' => array( 'Product' => array( 'id' => '3062', 'antibody_id' => null, 'name' => 'RNA Data Analysis', 'description' => '<p>Total RNA sequencing (RNA-Seq) detects both coding and noncoding RNAs and is typically used to measure gene and transcript abundance as well as to identify novel components of the transcriptome. Messenger RNA-Seq focuses on the quantification of gene expression, the identification of unknown transcripts, the discovery of alternative splicing and gene fusion events. And finally, small non-coding RNA sequencing (sncRNA-Seq) will detect small (<100 nucleotides long) RNAs that operate as key regulators in cellular processes.</p> <div class="extra-spaced"> <h2>What do we provide with the analysis?</h2> <p>This analysis provides information for either genes or isoforms with their expression levels.</p> <h3 class="diacol" style="font-weight: 100;">Standard Analysis</h3> <ul style="list-style-type: circle;"> <li>Summary statistics (total sequenced reads, total mapping reads, uniquely aligned reads, PCR duplicates, number of genes detected, average read density per gene, number of highly expressed genes, etc.)</li> <li>Trimmed and filtered reads in fastQ files after sequencing QC</li> <li>BAM sorted files from alignment to reference genome or transcriptome (indexed bam files and bigwig files included)</li> <li>Matrix with expression abundance obtained with specialized quantification tool MGCount (<a href="https://doi.org/10.1186/s12859-021-04544-3">software developed by Diagenode</a>). A table of MG communities linking each original feature in the GTF file with the resultant count matrix and metadata feature identifiers.</li> </ul> <h3 class="diacol" style="font-weight: 100;">Advanced Analysis</h3> <ul style="list-style-type: circle;"> <li>Comparative analysis (also called differential analysis) aimed at finding differentially expressed genes (DEGs) between two groups of samples</li> <li>Functional gene annotation</li> <li>Gene ontology enrichment analysis on DEGs</li> <li>Pathway enrichment analysis on DEGs (KEGG or DOSE for human samples)</li> <li>Alternative splicing analysis</li> <li>Gene fusion analysis</li> <li>Novel transcript identification</li> </ul> <h3 class="diacol" style="font-weight: 100;">Customized Analysis</h3> <p class="text-left">If you require a type of analysis that is not in the previous list, <a href="#" data-reveal-id="quoteModal-3062">please consult with our expert bioinformatics team</a>.</p> </div> <div><center><img src="https://www.diagenode.com/img/product/services/RNA-theorie.png" /></center></div> <p><a href="https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-021-04544-3">MGcount</a>: Diagenode has developed a bioinformatics software for counting whole-transcriptome RNA-seq reads from one or more input alignment files. It is specially designed to incorporate multi-mapping and multi-overlapping reads in the quantification using a flexible methodology that is compatible with any biotype. At the end of its execution, it produces a count matrix, compatible with any downstream analysis.</p> <center><img src="https://www.diagenode.com/img/product/services/mGcount-img.png" width="600px" /></center>', 'label1' => '', 'info1' => '', 'label2' => '', 'info2' => '', 'label3' => '', 'info3' => '', 'format' => '', 'catalog_number' => 'G02030005', 'old_catalog_number' => '', 'sf_code' => '', 'type' => 'ACC', 'search_order' => '', 'price_EUR' => '', 'price_USD' => '', 'price_GBP' => '', 'price_JPY' => '', 'price_CNY' => '', 'price_AUD' => '', 'country' => 'ALL', 'except_countries' => 'None', 'quote' => true, 'in_stock' => false, 'featured' => true, 'no_promo' => false, 'online' => true, 'master' => true, 'last_datasheet_update' => '', 'slug' => 'rna-data-analysis', 'meta_title' => 'RNA Data Analysis Services | Diagenode', 'meta_keywords' => '', 'meta_description' => 'RNA-seq data analysis service is made to extract information from a large variety of RNA-seq data (small RNA, mRNA and much more).', 'modified' => '2022-11-22 15:26:24', 'created' => '2020-03-26 10:04:58', 'locale' => 'eng' ), 'Antibody' => array( 'host' => '*****', 'id' => null, 'name' => null, 'description' => null, 'clonality' => null, 'isotype' => null, 'lot' => null, 'concentration' => null, 'reactivity' => null, 'type' => null, 'purity' => null, 'classification' => null, 'application_table' => null, 'storage_conditions' => null, 'storage_buffer' => null, 'precautions' => null, 'uniprot_acc' => null, 'slug' => null, 'meta_keywords' => null, 'meta_description' => null, 'modified' => null, 'created' => null, 'select_label' => null ), 'Slave' => array(), 'Group' => array(), 'Related' => array(), 'Application' => array(), 'Category' => array(), 'Document' => array(), 'Feature' => array(), 'Image' => array(), 'Promotion' => array(), 'Protocol' => array(), 'Publication' => array( (int) 0 => array( [maximum depth reached] ) ), 'Testimonial' => array(), 'Area' => array(), 'SafetySheet' => array() ), 'fromEmail' => 'dev.diagenode.com' ) $language = 'en' $meta_keywords = '' $meta_description = 'RNA-seq data analysis service is made to extract information from a large variety of RNA-seq data (small RNA, mRNA and much more).' $meta_title = 'RNA Data Analysis Services | Diagenode' $product = array( 'Product' => array( 'id' => '3062', 'antibody_id' => null, 'name' => 'RNA Data Analysis', 'description' => '<p>Total RNA sequencing (RNA-Seq) detects both coding and noncoding RNAs and is typically used to measure gene and transcript abundance as well as to identify novel components of the transcriptome. Messenger RNA-Seq focuses on the quantification of gene expression, the identification of unknown transcripts, the discovery of alternative splicing and gene fusion events. And finally, small non-coding RNA sequencing (sncRNA-Seq) will detect small (<100 nucleotides long) RNAs that operate as key regulators in cellular processes.</p> <div class="extra-spaced"> <h2>What do we provide with the analysis?</h2> <p>This analysis provides information for either genes or isoforms with their expression levels.</p> <h3 class="diacol" style="font-weight: 100;">Standard Analysis</h3> <ul style="list-style-type: circle;"> <li>Summary statistics (total sequenced reads, total mapping reads, uniquely aligned reads, PCR duplicates, number of genes detected, average read density per gene, number of highly expressed genes, etc.)</li> <li>Trimmed and filtered reads in fastQ files after sequencing QC</li> <li>BAM sorted files from alignment to reference genome or transcriptome (indexed bam files and bigwig files included)</li> <li>Matrix with expression abundance obtained with specialized quantification tool MGCount (<a href="https://doi.org/10.1186/s12859-021-04544-3">software developed by Diagenode</a>). A table of MG communities linking each original feature in the GTF file with the resultant count matrix and metadata feature identifiers.</li> </ul> <h3 class="diacol" style="font-weight: 100;">Advanced Analysis</h3> <ul style="list-style-type: circle;"> <li>Comparative analysis (also called differential analysis) aimed at finding differentially expressed genes (DEGs) between two groups of samples</li> <li>Functional gene annotation</li> <li>Gene ontology enrichment analysis on DEGs</li> <li>Pathway enrichment analysis on DEGs (KEGG or DOSE for human samples)</li> <li>Alternative splicing analysis</li> <li>Gene fusion analysis</li> <li>Novel transcript identification</li> </ul> <h3 class="diacol" style="font-weight: 100;">Customized Analysis</h3> <p class="text-left">If you require a type of analysis that is not in the previous list, <a href="#" data-reveal-id="quoteModal-3062">please consult with our expert bioinformatics team</a>.</p> </div> <div><center><img src="https://www.diagenode.com/img/product/services/RNA-theorie.png" /></center></div> <p><a href="https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-021-04544-3">MGcount</a>: Diagenode has developed a bioinformatics software for counting whole-transcriptome RNA-seq reads from one or more input alignment files. It is specially designed to incorporate multi-mapping and multi-overlapping reads in the quantification using a flexible methodology that is compatible with any biotype. At the end of its execution, it produces a count matrix, compatible with any downstream analysis.</p> <center><img src="https://www.diagenode.com/img/product/services/mGcount-img.png" width="600px" /></center>', 'label1' => '', 'info1' => '', 'label2' => '', 'info2' => '', 'label3' => '', 'info3' => '', 'format' => '', 'catalog_number' => 'G02030005', 'old_catalog_number' => '', 'sf_code' => '', 'type' => 'ACC', 'search_order' => '', 'price_EUR' => '', 'price_USD' => '', 'price_GBP' => '', 'price_JPY' => '', 'price_CNY' => '', 'price_AUD' => '', 'country' => 'ALL', 'except_countries' => 'None', 'quote' => true, 'in_stock' => false, 'featured' => true, 'no_promo' => false, 'online' => true, 'master' => true, 'last_datasheet_update' => '', 'slug' => 'rna-data-analysis', 'meta_title' => 'RNA Data Analysis Services | Diagenode', 'meta_keywords' => '', 'meta_description' => 'RNA-seq data analysis service is made to extract information from a large variety of RNA-seq data (small RNA, mRNA and much more).', 'modified' => '2022-11-22 15:26:24', 'created' => '2020-03-26 10:04:58', 'locale' => 'eng' ), 'Antibody' => array( 'host' => '*****', 'id' => null, 'name' => null, 'description' => null, 'clonality' => null, 'isotype' => null, 'lot' => null, 'concentration' => null, 'reactivity' => null, 'type' => null, 'purity' => null, 'classification' => null, 'application_table' => null, 'storage_conditions' => null, 'storage_buffer' => null, 'precautions' => null, 'uniprot_acc' => null, 'slug' => null, 'meta_keywords' => null, 'meta_description' => null, 'modified' => null, 'created' => null, 'select_label' => null ), 'Slave' => array(), 'Group' => array(), 'Related' => array(), 'Application' => array(), 'Category' => array(), 'Document' => array(), 'Feature' => array(), 'Image' => array(), 'Promotion' => array(), 'Protocol' => array(), 'Publication' => array( (int) 0 => array( 'id' => '4252', 'name' => 'MGcount: a total RNA-seq quantification tool to address multi-mappingand multi-overlapping alignments ambiguity in non-coding transcripts', 'authors' => 'Hita Andrea, Brocart Gilles, Fernandez Ana, Rehmsmeier Marc, Alemany Anna, Schvartzman Sol', 'description' => '<p>Background Total-RNA sequencing (total-RNA-seq) allows the simultaneous study of both the coding and the non-coding transcriptome. Yet, computational pipelines have traditionally focused on particular biotypes, making assumptions that are not fullfilled by total-RNA-seq datasets. Transcripts from distinct RNA biotypes vary in length, biogenesis, and function, can overlap in a genomic region, and may be present in the genome with a high copy number. Consequently, reads from total-RNA-seq libraries may cause ambiguous genomic alignments, demanding for flexible quantification approaches. Results Here we present Multi-Graph count (MGcount), a total-RNA-seq quantification tool combining two strategies for handling ambiguous alignments. First, MGcount assigns reads hierarchically to small-RNA and long-RNA features to account for length disparity when transcripts overlap in the same genomic position. Next, MGcount aggregates RNA products with similar sequences where reads systematically multi-map using a graph-based approach. MGcount outputs a transcriptomic count matrix compatible with RNA-sequencing downstream analysis pipelines, with both bulk and single-cell resolution, and the graphs that model repeated transcript structures for different biotypes. The software can be used as a python module or as a single-file executable program. Conclusions MGcount is a flexible total-RNA-seq quantification tool that successfully integrates reads that align to multiple genomic locations or that overlap with multiple gene features. Its approach is suitable for the simultaneous estimation of protein-coding, long non-coding and small non-coding transcript concentration, in both precursor and processed forms. Both source code and compiled software are available at https://github.com/hitaandrea/MGcount. Supplementary Information The online version contains supplementary material available at 10.1186/s12859-021-04544-3.</p>', 'date' => '2022-01-01', 'pmid' => 'https://www.ncbi.nlm.nih.gov/pubmed/35030988', 'doi' => '10.1186/s12859-021-04544-3', 'modified' => '2022-05-20 09:42:23', 'created' => '2022-05-19 10:41:50', 'ProductsPublication' => array( [maximum depth reached] ) ) ), 'Testimonial' => array(), 'Area' => array(), 'SafetySheet' => array() ) $fromEmail = 'dev.diagenode.com' $country = 'US' $countries_allowed = array( (int) 0 => 'CA', (int) 1 => 'US', (int) 2 => 'IE', (int) 3 => 'GB', (int) 4 => 'DK', (int) 5 => 'NO', (int) 6 => 'SE', (int) 7 => 'FI', (int) 8 => 'NL', (int) 9 => 'BE', (int) 10 => 'LU', (int) 11 => 'FR', (int) 12 => 'DE', (int) 13 => 'CH', (int) 14 => 'AT', (int) 15 => 'ES', (int) 16 => 'IT', (int) 17 => 'PT' ) $outsource = false $other_formats = array() $edit = '' $testimonials = '' $featured_testimonials = '' $related_products = '' $rrbs_service = array( (int) 0 => (int) 1894, (int) 1 => (int) 1895 ) $chipseq_service = array( (int) 0 => (int) 2683, (int) 1 => (int) 1835, (int) 2 => (int) 1836, (int) 3 => (int) 2684, (int) 4 => (int) 1838, (int) 5 => (int) 1839, (int) 6 => (int) 1856 ) $labelize = object(Closure) { } $old_catalog_number = '' $label = '<img src="/img/banners/banner-customizer-back.png" alt=""/>' $publication = array( 'id' => '4252', 'name' => 'MGcount: a total RNA-seq quantification tool to address multi-mappingand multi-overlapping alignments ambiguity in non-coding transcripts', 'authors' => 'Hita Andrea, Brocart Gilles, Fernandez Ana, Rehmsmeier Marc, Alemany Anna, Schvartzman Sol', 'description' => '<p>Background Total-RNA sequencing (total-RNA-seq) allows the simultaneous study of both the coding and the non-coding transcriptome. Yet, computational pipelines have traditionally focused on particular biotypes, making assumptions that are not fullfilled by total-RNA-seq datasets. Transcripts from distinct RNA biotypes vary in length, biogenesis, and function, can overlap in a genomic region, and may be present in the genome with a high copy number. Consequently, reads from total-RNA-seq libraries may cause ambiguous genomic alignments, demanding for flexible quantification approaches. Results Here we present Multi-Graph count (MGcount), a total-RNA-seq quantification tool combining two strategies for handling ambiguous alignments. First, MGcount assigns reads hierarchically to small-RNA and long-RNA features to account for length disparity when transcripts overlap in the same genomic position. Next, MGcount aggregates RNA products with similar sequences where reads systematically multi-map using a graph-based approach. MGcount outputs a transcriptomic count matrix compatible with RNA-sequencing downstream analysis pipelines, with both bulk and single-cell resolution, and the graphs that model repeated transcript structures for different biotypes. The software can be used as a python module or as a single-file executable program. Conclusions MGcount is a flexible total-RNA-seq quantification tool that successfully integrates reads that align to multiple genomic locations or that overlap with multiple gene features. Its approach is suitable for the simultaneous estimation of protein-coding, long non-coding and small non-coding transcript concentration, in both precursor and processed forms. Both source code and compiled software are available at https://github.com/hitaandrea/MGcount. Supplementary Information The online version contains supplementary material available at 10.1186/s12859-021-04544-3.</p>', 'date' => '2022-01-01', 'pmid' => 'https://www.ncbi.nlm.nih.gov/pubmed/35030988', 'doi' => '10.1186/s12859-021-04544-3', 'modified' => '2022-05-20 09:42:23', 'created' => '2022-05-19 10:41:50', 'ProductsPublication' => array( 'id' => '5682', 'product_id' => '3062', 'publication_id' => '4252' ) ) $externalLink = ' <a href="https://www.ncbi.nlm.nih.gov/pubmed/35030988" target="_blank"><i class="fa fa-external-link"></i></a>'CustomErrorHandler::handleError() - APP/Lib/CustomErrorHandler.php, line 9 include - APP/View/Products/view.ctp, line 747 View::_evaluate() - CORE/Cake/View/View.php, line 971 View::_render() - CORE/Cake/View/View.php, line 933 View::render() - CORE/Cake/View/View.php, line 473 Controller::render() - CORE/Cake/Controller/Controller.php, line 963 ProductsController::slug() - APP/Controller/ProductsController.php, line 1055 ReflectionMethod::invokeArgs() - [internal], line ?? Controller::invokeAction() - CORE/Cake/Controller/Controller.php, line 491 Dispatcher::_invoke() - CORE/Cake/Routing/Dispatcher.php, line 193 Dispatcher::dispatch() - CORE/Cake/Routing/Dispatcher.php, line 167 [main] - APP/webroot/index.php, line 118
(Notice): Undefined variable: message [APP/View/Products/view.ctp, line 747]Code Context$errorType = self::getErrorType($code);self::logToDatabase( $errorType, $description, $file, $line);return parent::handleError( $errorType, $description, $file, $line, $context);$viewFile = '/var/www/dev.diagenode.com/app/View/Products/view.ctp' $dataForView = array( 'language' => 'en', 'meta_keywords' => '', 'meta_description' => 'RNA-seq data analysis service is made to extract information from a large variety of RNA-seq data (small RNA, mRNA and much more).', 'meta_title' => 'RNA Data Analysis Services | Diagenode', 'product' => array( 'Product' => array( 'id' => '3062', 'antibody_id' => null, 'name' => 'RNA Data Analysis', 'description' => '<p>Total RNA sequencing (RNA-Seq) detects both coding and noncoding RNAs and is typically used to measure gene and transcript abundance as well as to identify novel components of the transcriptome. Messenger RNA-Seq focuses on the quantification of gene expression, the identification of unknown transcripts, the discovery of alternative splicing and gene fusion events. And finally, small non-coding RNA sequencing (sncRNA-Seq) will detect small (<100 nucleotides long) RNAs that operate as key regulators in cellular processes.</p> <div class="extra-spaced"> <h2>What do we provide with the analysis?</h2> <p>This analysis provides information for either genes or isoforms with their expression levels.</p> <h3 class="diacol" style="font-weight: 100;">Standard Analysis</h3> <ul style="list-style-type: circle;"> <li>Summary statistics (total sequenced reads, total mapping reads, uniquely aligned reads, PCR duplicates, number of genes detected, average read density per gene, number of highly expressed genes, etc.)</li> <li>Trimmed and filtered reads in fastQ files after sequencing QC</li> <li>BAM sorted files from alignment to reference genome or transcriptome (indexed bam files and bigwig files included)</li> <li>Matrix with expression abundance obtained with specialized quantification tool MGCount (<a href="https://doi.org/10.1186/s12859-021-04544-3">software developed by Diagenode</a>). A table of MG communities linking each original feature in the GTF file with the resultant count matrix and metadata feature identifiers.</li> </ul> <h3 class="diacol" style="font-weight: 100;">Advanced Analysis</h3> <ul style="list-style-type: circle;"> <li>Comparative analysis (also called differential analysis) aimed at finding differentially expressed genes (DEGs) between two groups of samples</li> <li>Functional gene annotation</li> <li>Gene ontology enrichment analysis on DEGs</li> <li>Pathway enrichment analysis on DEGs (KEGG or DOSE for human samples)</li> <li>Alternative splicing analysis</li> <li>Gene fusion analysis</li> <li>Novel transcript identification</li> </ul> <h3 class="diacol" style="font-weight: 100;">Customized Analysis</h3> <p class="text-left">If you require a type of analysis that is not in the previous list, <a href="#" data-reveal-id="quoteModal-3062">please consult with our expert bioinformatics team</a>.</p> </div> <div><center><img src="https://www.diagenode.com/img/product/services/RNA-theorie.png" /></center></div> <p><a href="https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-021-04544-3">MGcount</a>: Diagenode has developed a bioinformatics software for counting whole-transcriptome RNA-seq reads from one or more input alignment files. It is specially designed to incorporate multi-mapping and multi-overlapping reads in the quantification using a flexible methodology that is compatible with any biotype. At the end of its execution, it produces a count matrix, compatible with any downstream analysis.</p> <center><img src="https://www.diagenode.com/img/product/services/mGcount-img.png" width="600px" /></center>', 'label1' => '', 'info1' => '', 'label2' => '', 'info2' => '', 'label3' => '', 'info3' => '', 'format' => '', 'catalog_number' => 'G02030005', 'old_catalog_number' => '', 'sf_code' => '', 'type' => 'ACC', 'search_order' => '', 'price_EUR' => '', 'price_USD' => '', 'price_GBP' => '', 'price_JPY' => '', 'price_CNY' => '', 'price_AUD' => '', 'country' => 'ALL', 'except_countries' => 'None', 'quote' => true, 'in_stock' => false, 'featured' => true, 'no_promo' => false, 'online' => true, 'master' => true, 'last_datasheet_update' => '', 'slug' => 'rna-data-analysis', 'meta_title' => 'RNA Data Analysis Services | Diagenode', 'meta_keywords' => '', 'meta_description' => 'RNA-seq data analysis service is made to extract information from a large variety of RNA-seq data (small RNA, mRNA and much more).', 'modified' => '2022-11-22 15:26:24', 'created' => '2020-03-26 10:04:58', 'locale' => 'eng' ), 'Antibody' => array( 'host' => '*****', 'id' => null, 'name' => null, 'description' => null, 'clonality' => null, 'isotype' => null, 'lot' => null, 'concentration' => null, 'reactivity' => null, 'type' => null, 'purity' => null, 'classification' => null, 'application_table' => null, 'storage_conditions' => null, 'storage_buffer' => null, 'precautions' => null, 'uniprot_acc' => null, 'slug' => null, 'meta_keywords' => null, 'meta_description' => null, 'modified' => null, 'created' => null, 'select_label' => null ), 'Slave' => array(), 'Group' => array(), 'Related' => array(), 'Application' => array(), 'Category' => array(), 'Document' => array(), 'Feature' => array(), 'Image' => array(), 'Promotion' => array(), 'Protocol' => array(), 'Publication' => array( (int) 0 => array( [maximum depth reached] ) ), 'Testimonial' => array(), 'Area' => array(), 'SafetySheet' => array() ), 'fromEmail' => 'dev.diagenode.com' ) $language = 'en' $meta_keywords = '' $meta_description = 'RNA-seq data analysis service is made to extract information from a large variety of RNA-seq data (small RNA, mRNA and much more).' $meta_title = 'RNA Data Analysis Services | Diagenode' $product = array( 'Product' => array( 'id' => '3062', 'antibody_id' => null, 'name' => 'RNA Data Analysis', 'description' => '<p>Total RNA sequencing (RNA-Seq) detects both coding and noncoding RNAs and is typically used to measure gene and transcript abundance as well as to identify novel components of the transcriptome. Messenger RNA-Seq focuses on the quantification of gene expression, the identification of unknown transcripts, the discovery of alternative splicing and gene fusion events. And finally, small non-coding RNA sequencing (sncRNA-Seq) will detect small (<100 nucleotides long) RNAs that operate as key regulators in cellular processes.</p> <div class="extra-spaced"> <h2>What do we provide with the analysis?</h2> <p>This analysis provides information for either genes or isoforms with their expression levels.</p> <h3 class="diacol" style="font-weight: 100;">Standard Analysis</h3> <ul style="list-style-type: circle;"> <li>Summary statistics (total sequenced reads, total mapping reads, uniquely aligned reads, PCR duplicates, number of genes detected, average read density per gene, number of highly expressed genes, etc.)</li> <li>Trimmed and filtered reads in fastQ files after sequencing QC</li> <li>BAM sorted files from alignment to reference genome or transcriptome (indexed bam files and bigwig files included)</li> <li>Matrix with expression abundance obtained with specialized quantification tool MGCount (<a href="https://doi.org/10.1186/s12859-021-04544-3">software developed by Diagenode</a>). A table of MG communities linking each original feature in the GTF file with the resultant count matrix and metadata feature identifiers.</li> </ul> <h3 class="diacol" style="font-weight: 100;">Advanced Analysis</h3> <ul style="list-style-type: circle;"> <li>Comparative analysis (also called differential analysis) aimed at finding differentially expressed genes (DEGs) between two groups of samples</li> <li>Functional gene annotation</li> <li>Gene ontology enrichment analysis on DEGs</li> <li>Pathway enrichment analysis on DEGs (KEGG or DOSE for human samples)</li> <li>Alternative splicing analysis</li> <li>Gene fusion analysis</li> <li>Novel transcript identification</li> </ul> <h3 class="diacol" style="font-weight: 100;">Customized Analysis</h3> <p class="text-left">If you require a type of analysis that is not in the previous list, <a href="#" data-reveal-id="quoteModal-3062">please consult with our expert bioinformatics team</a>.</p> </div> <div><center><img src="https://www.diagenode.com/img/product/services/RNA-theorie.png" /></center></div> <p><a href="https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-021-04544-3">MGcount</a>: Diagenode has developed a bioinformatics software for counting whole-transcriptome RNA-seq reads from one or more input alignment files. It is specially designed to incorporate multi-mapping and multi-overlapping reads in the quantification using a flexible methodology that is compatible with any biotype. At the end of its execution, it produces a count matrix, compatible with any downstream analysis.</p> <center><img src="https://www.diagenode.com/img/product/services/mGcount-img.png" width="600px" /></center>', 'label1' => '', 'info1' => '', 'label2' => '', 'info2' => '', 'label3' => '', 'info3' => '', 'format' => '', 'catalog_number' => 'G02030005', 'old_catalog_number' => '', 'sf_code' => '', 'type' => 'ACC', 'search_order' => '', 'price_EUR' => '', 'price_USD' => '', 'price_GBP' => '', 'price_JPY' => '', 'price_CNY' => '', 'price_AUD' => '', 'country' => 'ALL', 'except_countries' => 'None', 'quote' => true, 'in_stock' => false, 'featured' => true, 'no_promo' => false, 'online' => true, 'master' => true, 'last_datasheet_update' => '', 'slug' => 'rna-data-analysis', 'meta_title' => 'RNA Data Analysis Services | Diagenode', 'meta_keywords' => '', 'meta_description' => 'RNA-seq data analysis service is made to extract information from a large variety of RNA-seq data (small RNA, mRNA and much more).', 'modified' => '2022-11-22 15:26:24', 'created' => '2020-03-26 10:04:58', 'locale' => 'eng' ), 'Antibody' => array( 'host' => '*****', 'id' => null, 'name' => null, 'description' => null, 'clonality' => null, 'isotype' => null, 'lot' => null, 'concentration' => null, 'reactivity' => null, 'type' => null, 'purity' => null, 'classification' => null, 'application_table' => null, 'storage_conditions' => null, 'storage_buffer' => null, 'precautions' => null, 'uniprot_acc' => null, 'slug' => null, 'meta_keywords' => null, 'meta_description' => null, 'modified' => null, 'created' => null, 'select_label' => null ), 'Slave' => array(), 'Group' => array(), 'Related' => array(), 'Application' => array(), 'Category' => array(), 'Document' => array(), 'Feature' => array(), 'Image' => array(), 'Promotion' => array(), 'Protocol' => array(), 'Publication' => array( (int) 0 => array( 'id' => '4252', 'name' => 'MGcount: a total RNA-seq quantification tool to address multi-mappingand multi-overlapping alignments ambiguity in non-coding transcripts', 'authors' => 'Hita Andrea, Brocart Gilles, Fernandez Ana, Rehmsmeier Marc, Alemany Anna, Schvartzman Sol', 'description' => '<p>Background Total-RNA sequencing (total-RNA-seq) allows the simultaneous study of both the coding and the non-coding transcriptome. Yet, computational pipelines have traditionally focused on particular biotypes, making assumptions that are not fullfilled by total-RNA-seq datasets. Transcripts from distinct RNA biotypes vary in length, biogenesis, and function, can overlap in a genomic region, and may be present in the genome with a high copy number. Consequently, reads from total-RNA-seq libraries may cause ambiguous genomic alignments, demanding for flexible quantification approaches. Results Here we present Multi-Graph count (MGcount), a total-RNA-seq quantification tool combining two strategies for handling ambiguous alignments. First, MGcount assigns reads hierarchically to small-RNA and long-RNA features to account for length disparity when transcripts overlap in the same genomic position. Next, MGcount aggregates RNA products with similar sequences where reads systematically multi-map using a graph-based approach. MGcount outputs a transcriptomic count matrix compatible with RNA-sequencing downstream analysis pipelines, with both bulk and single-cell resolution, and the graphs that model repeated transcript structures for different biotypes. The software can be used as a python module or as a single-file executable program. Conclusions MGcount is a flexible total-RNA-seq quantification tool that successfully integrates reads that align to multiple genomic locations or that overlap with multiple gene features. Its approach is suitable for the simultaneous estimation of protein-coding, long non-coding and small non-coding transcript concentration, in both precursor and processed forms. Both source code and compiled software are available at https://github.com/hitaandrea/MGcount. Supplementary Information The online version contains supplementary material available at 10.1186/s12859-021-04544-3.</p>', 'date' => '2022-01-01', 'pmid' => 'https://www.ncbi.nlm.nih.gov/pubmed/35030988', 'doi' => '10.1186/s12859-021-04544-3', 'modified' => '2022-05-20 09:42:23', 'created' => '2022-05-19 10:41:50', 'ProductsPublication' => array( [maximum depth reached] ) ) ), 'Testimonial' => array(), 'Area' => array(), 'SafetySheet' => array() ) $fromEmail = 'dev.diagenode.com' $country = 'US' $countries_allowed = array( (int) 0 => 'CA', (int) 1 => 'US', (int) 2 => 'IE', (int) 3 => 'GB', (int) 4 => 'DK', (int) 5 => 'NO', (int) 6 => 'SE', (int) 7 => 'FI', (int) 8 => 'NL', (int) 9 => 'BE', (int) 10 => 'LU', (int) 11 => 'FR', (int) 12 => 'DE', (int) 13 => 'CH', (int) 14 => 'AT', (int) 15 => 'ES', (int) 16 => 'IT', (int) 17 => 'PT' ) $outsource = false $other_formats = array() $edit = '' $testimonials = '' $featured_testimonials = '' $related_products = '' $rrbs_service = array( (int) 0 => (int) 1894, (int) 1 => (int) 1895 ) $chipseq_service = array( (int) 0 => (int) 2683, (int) 1 => (int) 1835, (int) 2 => (int) 1836, (int) 3 => (int) 2684, (int) 4 => (int) 1838, (int) 5 => (int) 1839, (int) 6 => (int) 1856 ) $labelize = object(Closure) { } $old_catalog_number = '' $label = '<img src="/img/banners/banner-customizer-back.png" alt=""/>' $publication = array( 'id' => '4252', 'name' => 'MGcount: a total RNA-seq quantification tool to address multi-mappingand multi-overlapping alignments ambiguity in non-coding transcripts', 'authors' => 'Hita Andrea, Brocart Gilles, Fernandez Ana, Rehmsmeier Marc, Alemany Anna, Schvartzman Sol', 'description' => '<p>Background Total-RNA sequencing (total-RNA-seq) allows the simultaneous study of both the coding and the non-coding transcriptome. Yet, computational pipelines have traditionally focused on particular biotypes, making assumptions that are not fullfilled by total-RNA-seq datasets. Transcripts from distinct RNA biotypes vary in length, biogenesis, and function, can overlap in a genomic region, and may be present in the genome with a high copy number. Consequently, reads from total-RNA-seq libraries may cause ambiguous genomic alignments, demanding for flexible quantification approaches. Results Here we present Multi-Graph count (MGcount), a total-RNA-seq quantification tool combining two strategies for handling ambiguous alignments. First, MGcount assigns reads hierarchically to small-RNA and long-RNA features to account for length disparity when transcripts overlap in the same genomic position. Next, MGcount aggregates RNA products with similar sequences where reads systematically multi-map using a graph-based approach. MGcount outputs a transcriptomic count matrix compatible with RNA-sequencing downstream analysis pipelines, with both bulk and single-cell resolution, and the graphs that model repeated transcript structures for different biotypes. The software can be used as a python module or as a single-file executable program. Conclusions MGcount is a flexible total-RNA-seq quantification tool that successfully integrates reads that align to multiple genomic locations or that overlap with multiple gene features. Its approach is suitable for the simultaneous estimation of protein-coding, long non-coding and small non-coding transcript concentration, in both precursor and processed forms. Both source code and compiled software are available at https://github.com/hitaandrea/MGcount. Supplementary Information The online version contains supplementary material available at 10.1186/s12859-021-04544-3.</p>', 'date' => '2022-01-01', 'pmid' => 'https://www.ncbi.nlm.nih.gov/pubmed/35030988', 'doi' => '10.1186/s12859-021-04544-3', 'modified' => '2022-05-20 09:42:23', 'created' => '2022-05-19 10:41:50', 'ProductsPublication' => array( 'id' => '5682', 'product_id' => '3062', 'publication_id' => '4252' ) ) $externalLink = ' <a href="https://www.ncbi.nlm.nih.gov/pubmed/35030988" target="_blank"><i class="fa fa-external-link"></i></a>'CustomErrorHandler::handleError() - APP/Lib/CustomErrorHandler.php, line 9 include - APP/View/Products/view.ctp, line 747 View::_evaluate() - CORE/Cake/View/View.php, line 971 View::_render() - CORE/Cake/View/View.php, line 933 View::render() - CORE/Cake/View/View.php, line 473 Controller::render() - CORE/Cake/Controller/Controller.php, line 963 ProductsController::slug() - APP/Controller/ProductsController.php, line 1055 ReflectionMethod::invokeArgs() - [internal], line ?? Controller::invokeAction() - CORE/Cake/Controller/Controller.php, line 491 Dispatcher::_invoke() - CORE/Cake/Routing/Dispatcher.php, line 193 Dispatcher::dispatch() - CORE/Cake/Routing/Dispatcher.php, line 167 [main] - APP/webroot/index.php, line 118
(Notice): Undefined variable: campaign_id [APP/View/Products/view.ctp, line 747]Code Context$errorType = self::getErrorType($code);self::logToDatabase( $errorType, $description, $file, $line);return parent::handleError( $errorType, $description, $file, $line, $context);$viewFile = '/var/www/dev.diagenode.com/app/View/Products/view.ctp' $dataForView = array( 'language' => 'en', 'meta_keywords' => '', 'meta_description' => 'RNA-seq data analysis service is made to extract information from a large variety of RNA-seq data (small RNA, mRNA and much more).', 'meta_title' => 'RNA Data Analysis Services | Diagenode', 'product' => array( 'Product' => array( 'id' => '3062', 'antibody_id' => null, 'name' => 'RNA Data Analysis', 'description' => '<p>Total RNA sequencing (RNA-Seq) detects both coding and noncoding RNAs and is typically used to measure gene and transcript abundance as well as to identify novel components of the transcriptome. Messenger RNA-Seq focuses on the quantification of gene expression, the identification of unknown transcripts, the discovery of alternative splicing and gene fusion events. And finally, small non-coding RNA sequencing (sncRNA-Seq) will detect small (<100 nucleotides long) RNAs that operate as key regulators in cellular processes.</p> <div class="extra-spaced"> <h2>What do we provide with the analysis?</h2> <p>This analysis provides information for either genes or isoforms with their expression levels.</p> <h3 class="diacol" style="font-weight: 100;">Standard Analysis</h3> <ul style="list-style-type: circle;"> <li>Summary statistics (total sequenced reads, total mapping reads, uniquely aligned reads, PCR duplicates, number of genes detected, average read density per gene, number of highly expressed genes, etc.)</li> <li>Trimmed and filtered reads in fastQ files after sequencing QC</li> <li>BAM sorted files from alignment to reference genome or transcriptome (indexed bam files and bigwig files included)</li> <li>Matrix with expression abundance obtained with specialized quantification tool MGCount (<a href="https://doi.org/10.1186/s12859-021-04544-3">software developed by Diagenode</a>). A table of MG communities linking each original feature in the GTF file with the resultant count matrix and metadata feature identifiers.</li> </ul> <h3 class="diacol" style="font-weight: 100;">Advanced Analysis</h3> <ul style="list-style-type: circle;"> <li>Comparative analysis (also called differential analysis) aimed at finding differentially expressed genes (DEGs) between two groups of samples</li> <li>Functional gene annotation</li> <li>Gene ontology enrichment analysis on DEGs</li> <li>Pathway enrichment analysis on DEGs (KEGG or DOSE for human samples)</li> <li>Alternative splicing analysis</li> <li>Gene fusion analysis</li> <li>Novel transcript identification</li> </ul> <h3 class="diacol" style="font-weight: 100;">Customized Analysis</h3> <p class="text-left">If you require a type of analysis that is not in the previous list, <a href="#" data-reveal-id="quoteModal-3062">please consult with our expert bioinformatics team</a>.</p> </div> <div><center><img src="https://www.diagenode.com/img/product/services/RNA-theorie.png" /></center></div> <p><a href="https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-021-04544-3">MGcount</a>: Diagenode has developed a bioinformatics software for counting whole-transcriptome RNA-seq reads from one or more input alignment files. It is specially designed to incorporate multi-mapping and multi-overlapping reads in the quantification using a flexible methodology that is compatible with any biotype. At the end of its execution, it produces a count matrix, compatible with any downstream analysis.</p> <center><img src="https://www.diagenode.com/img/product/services/mGcount-img.png" width="600px" /></center>', 'label1' => '', 'info1' => '', 'label2' => '', 'info2' => '', 'label3' => '', 'info3' => '', 'format' => '', 'catalog_number' => 'G02030005', 'old_catalog_number' => '', 'sf_code' => '', 'type' => 'ACC', 'search_order' => '', 'price_EUR' => '', 'price_USD' => '', 'price_GBP' => '', 'price_JPY' => '', 'price_CNY' => '', 'price_AUD' => '', 'country' => 'ALL', 'except_countries' => 'None', 'quote' => true, 'in_stock' => false, 'featured' => true, 'no_promo' => false, 'online' => true, 'master' => true, 'last_datasheet_update' => '', 'slug' => 'rna-data-analysis', 'meta_title' => 'RNA Data Analysis Services | Diagenode', 'meta_keywords' => '', 'meta_description' => 'RNA-seq data analysis service is made to extract information from a large variety of RNA-seq data (small RNA, mRNA and much more).', 'modified' => '2022-11-22 15:26:24', 'created' => '2020-03-26 10:04:58', 'locale' => 'eng' ), 'Antibody' => array( 'host' => '*****', 'id' => null, 'name' => null, 'description' => null, 'clonality' => null, 'isotype' => null, 'lot' => null, 'concentration' => null, 'reactivity' => null, 'type' => null, 'purity' => null, 'classification' => null, 'application_table' => null, 'storage_conditions' => null, 'storage_buffer' => null, 'precautions' => null, 'uniprot_acc' => null, 'slug' => null, 'meta_keywords' => null, 'meta_description' => null, 'modified' => null, 'created' => null, 'select_label' => null ), 'Slave' => array(), 'Group' => array(), 'Related' => array(), 'Application' => array(), 'Category' => array(), 'Document' => array(), 'Feature' => array(), 'Image' => array(), 'Promotion' => array(), 'Protocol' => array(), 'Publication' => array( (int) 0 => array( [maximum depth reached] ) ), 'Testimonial' => array(), 'Area' => array(), 'SafetySheet' => array() ), 'fromEmail' => 'dev.diagenode.com' ) $language = 'en' $meta_keywords = '' $meta_description = 'RNA-seq data analysis service is made to extract information from a large variety of RNA-seq data (small RNA, mRNA and much more).' $meta_title = 'RNA Data Analysis Services | Diagenode' $product = array( 'Product' => array( 'id' => '3062', 'antibody_id' => null, 'name' => 'RNA Data Analysis', 'description' => '<p>Total RNA sequencing (RNA-Seq) detects both coding and noncoding RNAs and is typically used to measure gene and transcript abundance as well as to identify novel components of the transcriptome. Messenger RNA-Seq focuses on the quantification of gene expression, the identification of unknown transcripts, the discovery of alternative splicing and gene fusion events. And finally, small non-coding RNA sequencing (sncRNA-Seq) will detect small (<100 nucleotides long) RNAs that operate as key regulators in cellular processes.</p> <div class="extra-spaced"> <h2>What do we provide with the analysis?</h2> <p>This analysis provides information for either genes or isoforms with their expression levels.</p> <h3 class="diacol" style="font-weight: 100;">Standard Analysis</h3> <ul style="list-style-type: circle;"> <li>Summary statistics (total sequenced reads, total mapping reads, uniquely aligned reads, PCR duplicates, number of genes detected, average read density per gene, number of highly expressed genes, etc.)</li> <li>Trimmed and filtered reads in fastQ files after sequencing QC</li> <li>BAM sorted files from alignment to reference genome or transcriptome (indexed bam files and bigwig files included)</li> <li>Matrix with expression abundance obtained with specialized quantification tool MGCount (<a href="https://doi.org/10.1186/s12859-021-04544-3">software developed by Diagenode</a>). A table of MG communities linking each original feature in the GTF file with the resultant count matrix and metadata feature identifiers.</li> </ul> <h3 class="diacol" style="font-weight: 100;">Advanced Analysis</h3> <ul style="list-style-type: circle;"> <li>Comparative analysis (also called differential analysis) aimed at finding differentially expressed genes (DEGs) between two groups of samples</li> <li>Functional gene annotation</li> <li>Gene ontology enrichment analysis on DEGs</li> <li>Pathway enrichment analysis on DEGs (KEGG or DOSE for human samples)</li> <li>Alternative splicing analysis</li> <li>Gene fusion analysis</li> <li>Novel transcript identification</li> </ul> <h3 class="diacol" style="font-weight: 100;">Customized Analysis</h3> <p class="text-left">If you require a type of analysis that is not in the previous list, <a href="#" data-reveal-id="quoteModal-3062">please consult with our expert bioinformatics team</a>.</p> </div> <div><center><img src="https://www.diagenode.com/img/product/services/RNA-theorie.png" /></center></div> <p><a href="https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-021-04544-3">MGcount</a>: Diagenode has developed a bioinformatics software for counting whole-transcriptome RNA-seq reads from one or more input alignment files. It is specially designed to incorporate multi-mapping and multi-overlapping reads in the quantification using a flexible methodology that is compatible with any biotype. At the end of its execution, it produces a count matrix, compatible with any downstream analysis.</p> <center><img src="https://www.diagenode.com/img/product/services/mGcount-img.png" width="600px" /></center>', 'label1' => '', 'info1' => '', 'label2' => '', 'info2' => '', 'label3' => '', 'info3' => '', 'format' => '', 'catalog_number' => 'G02030005', 'old_catalog_number' => '', 'sf_code' => '', 'type' => 'ACC', 'search_order' => '', 'price_EUR' => '', 'price_USD' => '', 'price_GBP' => '', 'price_JPY' => '', 'price_CNY' => '', 'price_AUD' => '', 'country' => 'ALL', 'except_countries' => 'None', 'quote' => true, 'in_stock' => false, 'featured' => true, 'no_promo' => false, 'online' => true, 'master' => true, 'last_datasheet_update' => '', 'slug' => 'rna-data-analysis', 'meta_title' => 'RNA Data Analysis Services | Diagenode', 'meta_keywords' => '', 'meta_description' => 'RNA-seq data analysis service is made to extract information from a large variety of RNA-seq data (small RNA, mRNA and much more).', 'modified' => '2022-11-22 15:26:24', 'created' => '2020-03-26 10:04:58', 'locale' => 'eng' ), 'Antibody' => array( 'host' => '*****', 'id' => null, 'name' => null, 'description' => null, 'clonality' => null, 'isotype' => null, 'lot' => null, 'concentration' => null, 'reactivity' => null, 'type' => null, 'purity' => null, 'classification' => null, 'application_table' => null, 'storage_conditions' => null, 'storage_buffer' => null, 'precautions' => null, 'uniprot_acc' => null, 'slug' => null, 'meta_keywords' => null, 'meta_description' => null, 'modified' => null, 'created' => null, 'select_label' => null ), 'Slave' => array(), 'Group' => array(), 'Related' => array(), 'Application' => array(), 'Category' => array(), 'Document' => array(), 'Feature' => array(), 'Image' => array(), 'Promotion' => array(), 'Protocol' => array(), 'Publication' => array( (int) 0 => array( 'id' => '4252', 'name' => 'MGcount: a total RNA-seq quantification tool to address multi-mappingand multi-overlapping alignments ambiguity in non-coding transcripts', 'authors' => 'Hita Andrea, Brocart Gilles, Fernandez Ana, Rehmsmeier Marc, Alemany Anna, Schvartzman Sol', 'description' => '<p>Background Total-RNA sequencing (total-RNA-seq) allows the simultaneous study of both the coding and the non-coding transcriptome. Yet, computational pipelines have traditionally focused on particular biotypes, making assumptions that are not fullfilled by total-RNA-seq datasets. Transcripts from distinct RNA biotypes vary in length, biogenesis, and function, can overlap in a genomic region, and may be present in the genome with a high copy number. Consequently, reads from total-RNA-seq libraries may cause ambiguous genomic alignments, demanding for flexible quantification approaches. Results Here we present Multi-Graph count (MGcount), a total-RNA-seq quantification tool combining two strategies for handling ambiguous alignments. First, MGcount assigns reads hierarchically to small-RNA and long-RNA features to account for length disparity when transcripts overlap in the same genomic position. Next, MGcount aggregates RNA products with similar sequences where reads systematically multi-map using a graph-based approach. MGcount outputs a transcriptomic count matrix compatible with RNA-sequencing downstream analysis pipelines, with both bulk and single-cell resolution, and the graphs that model repeated transcript structures for different biotypes. The software can be used as a python module or as a single-file executable program. Conclusions MGcount is a flexible total-RNA-seq quantification tool that successfully integrates reads that align to multiple genomic locations or that overlap with multiple gene features. Its approach is suitable for the simultaneous estimation of protein-coding, long non-coding and small non-coding transcript concentration, in both precursor and processed forms. Both source code and compiled software are available at https://github.com/hitaandrea/MGcount. Supplementary Information The online version contains supplementary material available at 10.1186/s12859-021-04544-3.</p>', 'date' => '2022-01-01', 'pmid' => 'https://www.ncbi.nlm.nih.gov/pubmed/35030988', 'doi' => '10.1186/s12859-021-04544-3', 'modified' => '2022-05-20 09:42:23', 'created' => '2022-05-19 10:41:50', 'ProductsPublication' => array( [maximum depth reached] ) ) ), 'Testimonial' => array(), 'Area' => array(), 'SafetySheet' => array() ) $fromEmail = 'dev.diagenode.com' $country = 'US' $countries_allowed = array( (int) 0 => 'CA', (int) 1 => 'US', (int) 2 => 'IE', (int) 3 => 'GB', (int) 4 => 'DK', (int) 5 => 'NO', (int) 6 => 'SE', (int) 7 => 'FI', (int) 8 => 'NL', (int) 9 => 'BE', (int) 10 => 'LU', (int) 11 => 'FR', (int) 12 => 'DE', (int) 13 => 'CH', (int) 14 => 'AT', (int) 15 => 'ES', (int) 16 => 'IT', (int) 17 => 'PT' ) $outsource = false $other_formats = array() $edit = '' $testimonials = '' $featured_testimonials = '' $related_products = '' $rrbs_service = array( (int) 0 => (int) 1894, (int) 1 => (int) 1895 ) $chipseq_service = array( (int) 0 => (int) 2683, (int) 1 => (int) 1835, (int) 2 => (int) 1836, (int) 3 => (int) 2684, (int) 4 => (int) 1838, (int) 5 => (int) 1839, (int) 6 => (int) 1856 ) $labelize = object(Closure) { } $old_catalog_number = '' $label = '<img src="/img/banners/banner-customizer-back.png" alt=""/>' $publication = array( 'id' => '4252', 'name' => 'MGcount: a total RNA-seq quantification tool to address multi-mappingand multi-overlapping alignments ambiguity in non-coding transcripts', 'authors' => 'Hita Andrea, Brocart Gilles, Fernandez Ana, Rehmsmeier Marc, Alemany Anna, Schvartzman Sol', 'description' => '<p>Background Total-RNA sequencing (total-RNA-seq) allows the simultaneous study of both the coding and the non-coding transcriptome. Yet, computational pipelines have traditionally focused on particular biotypes, making assumptions that are not fullfilled by total-RNA-seq datasets. Transcripts from distinct RNA biotypes vary in length, biogenesis, and function, can overlap in a genomic region, and may be present in the genome with a high copy number. Consequently, reads from total-RNA-seq libraries may cause ambiguous genomic alignments, demanding for flexible quantification approaches. Results Here we present Multi-Graph count (MGcount), a total-RNA-seq quantification tool combining two strategies for handling ambiguous alignments. First, MGcount assigns reads hierarchically to small-RNA and long-RNA features to account for length disparity when transcripts overlap in the same genomic position. Next, MGcount aggregates RNA products with similar sequences where reads systematically multi-map using a graph-based approach. MGcount outputs a transcriptomic count matrix compatible with RNA-sequencing downstream analysis pipelines, with both bulk and single-cell resolution, and the graphs that model repeated transcript structures for different biotypes. The software can be used as a python module or as a single-file executable program. Conclusions MGcount is a flexible total-RNA-seq quantification tool that successfully integrates reads that align to multiple genomic locations or that overlap with multiple gene features. Its approach is suitable for the simultaneous estimation of protein-coding, long non-coding and small non-coding transcript concentration, in both precursor and processed forms. Both source code and compiled software are available at https://github.com/hitaandrea/MGcount. Supplementary Information The online version contains supplementary material available at 10.1186/s12859-021-04544-3.</p>', 'date' => '2022-01-01', 'pmid' => 'https://www.ncbi.nlm.nih.gov/pubmed/35030988', 'doi' => '10.1186/s12859-021-04544-3', 'modified' => '2022-05-20 09:42:23', 'created' => '2022-05-19 10:41:50', 'ProductsPublication' => array( 'id' => '5682', 'product_id' => '3062', 'publication_id' => '4252' ) ) $externalLink = ' <a href="https://www.ncbi.nlm.nih.gov/pubmed/35030988" target="_blank"><i class="fa fa-external-link"></i></a>'CustomErrorHandler::handleError() - APP/Lib/CustomErrorHandler.php, line 9 include - APP/View/Products/view.ctp, line 747 View::_evaluate() - CORE/Cake/View/View.php, line 971 View::_render() - CORE/Cake/View/View.php, line 933 View::render() - CORE/Cake/View/View.php, line 473 Controller::render() - CORE/Cake/Controller/Controller.php, line 963 ProductsController::slug() - APP/Controller/ProductsController.php, line 1055 ReflectionMethod::invokeArgs() - [internal], line ?? Controller::invokeAction() - CORE/Cake/Controller/Controller.php, line 491 Dispatcher::_invoke() - CORE/Cake/Routing/Dispatcher.php, line 193 Dispatcher::dispatch() - CORE/Cake/Routing/Dispatcher.php, line 167 [main] - APP/webroot/index.php, line 118